

Bartosz Woźniak
I keep seeing the same mistake in different costumes. Someone wants to make life easier — usually by writing a bit of automation, or by centralising something that feels scattered — and the fix quietly points the dependency arrows the wrong way. Weeks later, the thing that was supposed to help is the thing everyone has to work around.
The classic version goes like this. Your team maintains an internal package. You cut a new version, and three services need to pick it up. The obvious move is to write a post-release action that opens PRs in every consumer repo:
It feels productive. But look at what just happened. The library repo now has to know who uses it, hold credentials to push into those repos, and somehow handle breakages it cannot reproduce locally. The library has started depending on its consumers.
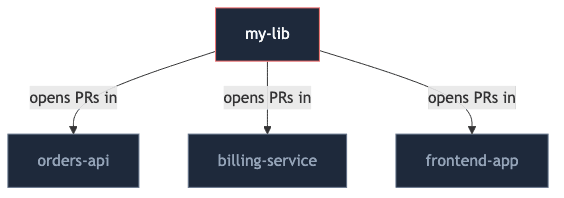
That is exactly what the Dependency Inversion Principle tells you not to do.
The fix is to flip the arrow. Each consumer watches the registry (or runs Dependabot / Renovate) and decides on its own schedule when to upgrade. The library publishes a version and forgets who is listening:
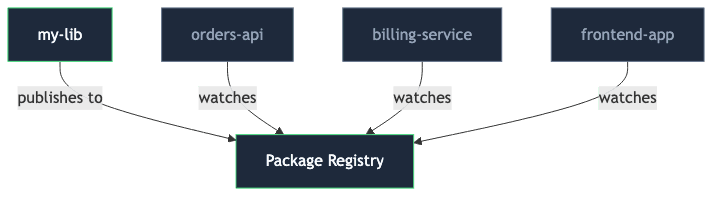
DIP, the D in SOLID, is usually explained with class diagrams and abstract interfaces — and it was coined in that context. But the underlying heuristic transfers cleanly to distributed systems, build pipelines, and infrastructure: high-level modules should not depend on low-level ones, both should depend on an abstraction. Or, more bluntly —
If your upstream component is keeping a list of the downstream things that use it, the arrows are pointing the wrong way.
That “list” is the tell. It might be a list of consumer repos, a list of caller services, a list of webhook subscribers, a list of app names inside a build script, a list of environments inside a Terraform module. Whenever I spot one, I know there is probably an inversion hiding underneath.
The rest of this post is a tour of that same mistake, wearing seven different uniforms.
1. The shared database schema
A users table has a full_name column. Auth reads it, billing reads it, a nightly analytics job reads it:
The team that owns users decides to split the column into first_name and last_name. They ship the migration on a Friday afternoon:
Over the weekend, billing’s invoice PDFs come out blank:
Nobody did anything wrong. The schema was acting as a public API with no contract, and the team that owned it had no real way to know who depended on what shape. They had accidentally become the change-management board for the whole company.
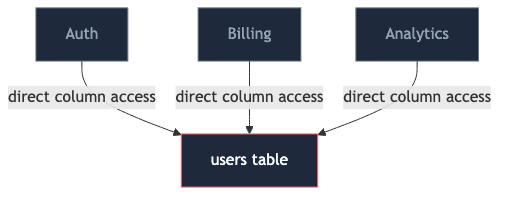
That is the inversion: the schema, which should be the low-level detail, ended up being something every other service directly binds to.
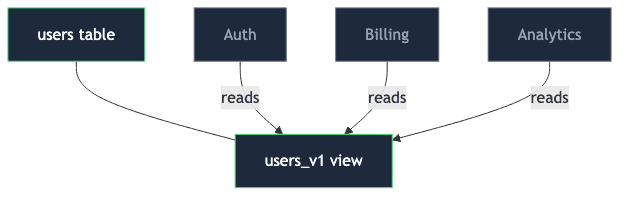
The honest fix is boring: introduce a thin, versioned contract between the table and the readers. A database view that presents a stable shape while the underlying table evolves freely:
Readers see full_name for as long as they ask for it; the underlying schema is free to change. Writes are a different story — they get pointed at the new columns directly, or wrapped in an INSTEAD OF trigger that splits the value on the way in (with the small irony that the trigger still has to call split_part, just on the other side of the boundary). When the next breaking change lands, users_v2 ships next to users_v1, readers migrate on their own schedule, and v1 retires once nothing reads it.
2. Service-to-service shapes
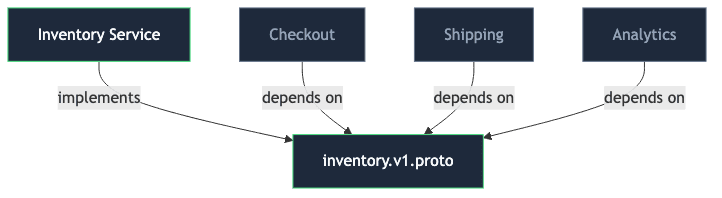
The checkout service calls inventory via GET /items/:id and reads response.stock:
Six months later, inventory wants to return per-warehouse stock as an object. They cannot — checkout will crash:
So inventory adds /v2/items/:id, and now they maintain both forever. Five more callers appear, each pinned to a slightly different shape, and inventory’s “simple” endpoint becomes a museum of other teams’ assumptions:
The tell here is subtle: there is no explicit list of callers, but inventory behaves as if there is one. Every deprecation discussion turns into an archaeology project — “who still hits v1?”, “can we sunset the flat stock field?”, “let’s grep the other repos.”
A shared contract — a protobuf schema that both sides depend on — pulls the arrows back into line:
This is a new contract — existing callers migrate to it rather than getting a silent drop-in replacement. The point is not magic backward compatibility; it is that evolution is coordinated through the schema, not through ad-hoc archaeology across every consumer repo.
Inventory evolves the contract, not the callers. Callers depend on the contract, not on inventory’s internal shape.
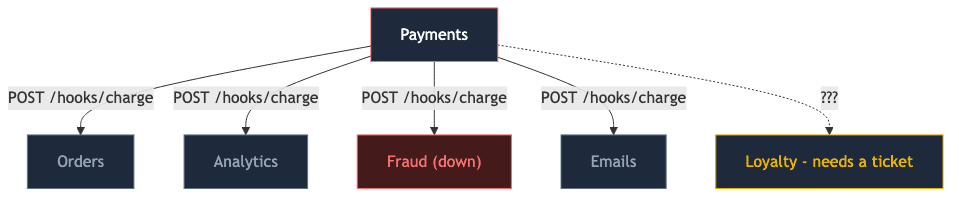
3. Webhooks with a Rolodex
Payments fires a charge.succeeded event, and in its config is a hardcoded list:
A new loyalty team spins up and needs the event. They file a ticket against payments. Payments is now a routing table; when fraud is down, retries pile up, queues grow, and charges stall behind a service payments should not even know about.
Publishing to a topic flips this cleanly. Payments emits charge.succeeded and forgets who is listening:
Consumers subscribe on their own schedule, and the list of subscribers lives in the one place that genuinely cares about it — the broker — rather than in the service that shouldn’t:
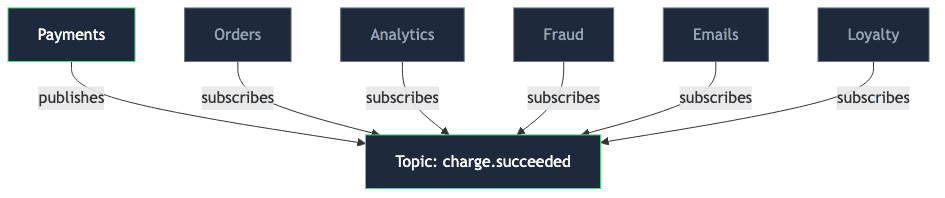
No ticket. No merge into payments. Loyalty is live.
4. The monorepo build that knows every app
The root build config has a giant switch:
A new team wants to add a Rust service. They cannot ship until the platform team merges a PR into the root Makefile. The platform team becomes a bottleneck for every new project, and the build file becomes a bulletin board of everyone else’s quirks.
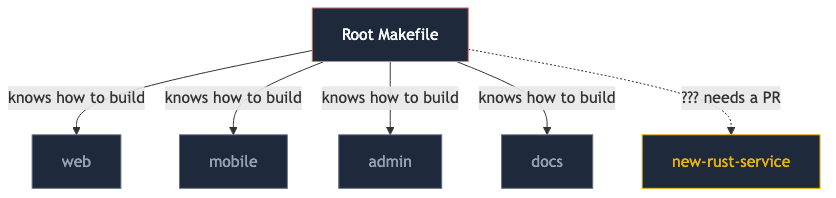
The inversion is that the build system holds the list of apps. The fix is for each app to declare how it builds — a standard target in its own directory — and the platform depends only on the abstraction “an app knows how to build itself:”
The root build just discovers and delegates:
New team adds their directory, adds a Makefile with a build target, and they’re shipping. Zero coordination.
5. Shared CI with app-specific patches
The central ci.yml in the platform repo has if: matrix.repo == 'checkout' blocks scattered throughout:
When the platform team upgrades the runner image, something breaks for one specific app and rolls back the whole pipeline. Every conditional branch is a coupling between the platform and a specific consumer.
The fix has the same shape as the build system: a reusable workflow that takes inputs, called from each app’s own repo:
Platform owns the skeleton; apps own the flesh. No more if: matrix.repo == conditionals. No more cross-repo rollbacks. That said, the input list — run-e2e, run-unit-tests — is its own quiet roster: add a new step type and you are back to filing a platform PR to add an input. If there is a strong reason to keep CI logic centralised — enforcing org-wide security scans, managing a shared runner pool, or satisfying compliance requirements — the reusable workflow is the right tool. If the only reason is that it feels tidy, each app owning its workflow entirely is often the cleaner cut.
6. Terraform modules with baked-in environments
A modules/vpc/main.tf contains a hardcoded environment roster:
A new region is funded — eu-west-1 prod goes in. Someone edits the module. The diff plan shows changes to every existing environment at once, and everyone panics, because a shared module change has just become a company-wide event.
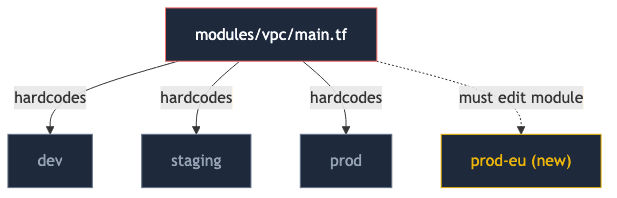
The module knows which environments exist and what each one is for. Both of those are facts that belong to the caller. The module should depend on the abstraction “an environment config” and let whoever instantiates it supply the name and the shape:
Each environment instantiates the module on its own terms:
The plan for prod-eu touches nothing in prod-us. The module is stable; the callers supply the variance.
7. Tests that stub at the HTTP boundary
An order service notifies a shipping provider when an order is placed. The production code calls the provider directly:
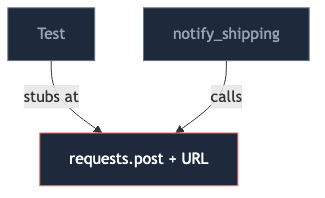
There is no abstraction, so the tests are forced to reach down and stub at the HTTP layer:
The test now knows the URL, the HTTP method, the auth header format, and the exact wire shape. Switch providers and every test needs new URLs. The test suite has become a roster of implementation details — the same tell, one layer down:
The fix is to introduce an abstraction the service code depends on, and let the test inject a fake through that same seam:
The test provides its own implementation of the protocol — no HTTP involved:
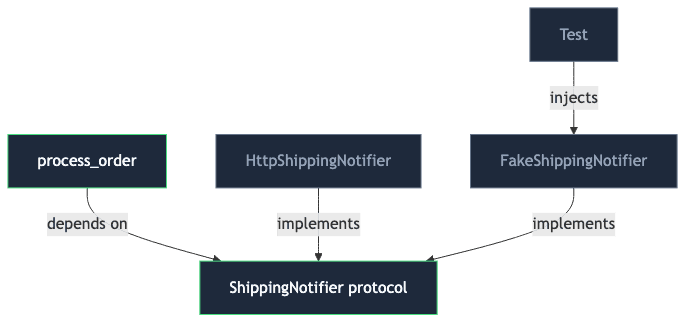
The test knows nothing about HTTP. Swap providers — only the adapter changes, and the tests stay green.
Common denominator
Looking at the seven side by side, the shape is almost comical:
Database:
userstable schema → list of reader services.API:
inventoryendpoint → list of versioned endpoints maintained per caller's assumed shape.Events:
paymentswebhook config → list of subscriber urls.Build: Root
Makefile→ list of app names and build commands.CI: Shared
ci.yml→ list of repo-specific conditionals.Infra: Terraform module → list of environment names and sizes.
Tests:
notify_shippingfunction → list of urls, methods, and wire shapes.
Different layer, same mistake. The thing that should be stable and depended-upon is instead reaching outward and collecting dependencies on everything that uses it. That roster — whatever form it takes — is the clearest signal I know of that a design has been quietly inverted.
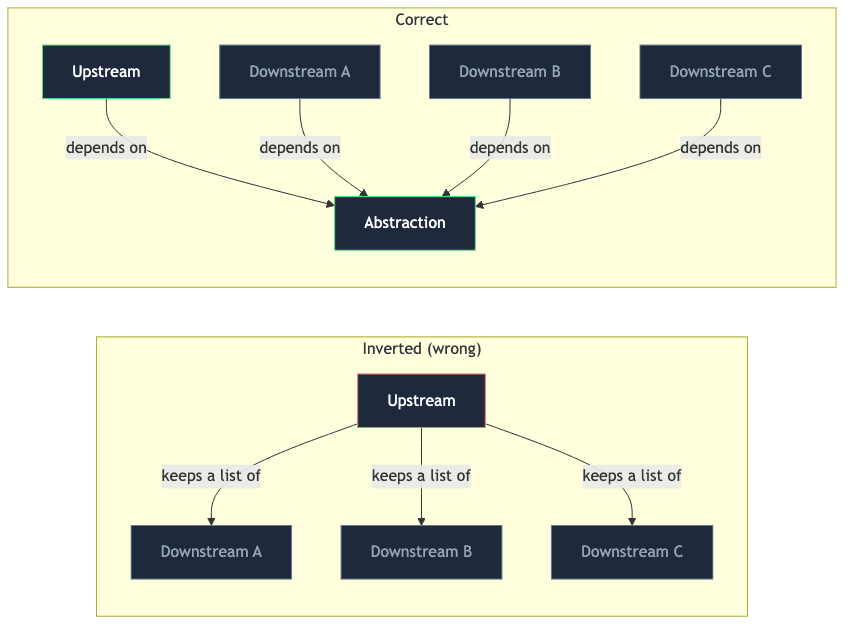
When you feel the urge to centralise or automate, pause and check which way the arrows point. If your fix requires an upstream component to keep a list of downstream things, you are not solving the problem — you are encoding it.

